
With the EnMasse 0.28.0 release, using a Gitops workflow to manage your messaging application is even easier than before. This article explores the service model of EnMasse and how it maps to a Gitops workflow.
Gitops is a way to do Continuous Delivery where not only the source code of an application, but all configuration of an application is stored in git. Changes to a production environment involve creating a pull/change requests to a git repository. Once the PR has been tested and reviewed, it can be merged. When merged, a CD job is triggered that will apply the current state of the git repository to the system. There are variants of this where you run A/B testing and so on, the sky is the limit!
The declarative nature of the “gitops model” fits well with the declarative nature of Kubernetes. You can store your Kubernetes configuration in git, and trigger some process to apply the configuration to a Kubernetes cluster. If you store your application code together with the Kubernetes configuration, you enable development teams to be in full control of their application deployment to any cluster environment.
Traditionally, Kubernetes has mainly been used for stateless services. Stateful services are usually running outside the Kubernetes cluster. If a development team wants to use a stateful service, the team normally have to install and manage the service themselves or use a cloud provider service. This is changing with the introduction of all sorts of operators for Postgresql, Kafka, Elasticsearch etc.
EnMasse is an operator of a stateful messaging service that runs on Kuberentes, with the explicit distinction that the responsibility of operating the messaging service is separate from the tenants consuming it. This makes it easy for an operations team to use the gitops model to manage EnMasse, and for the development teams to use the gitops model to manage their messaging configuration.
Lets assume that you have a team in your organization managing the messaging infrastructure using EnMasse on Kubernetes or OpenShift, and that you have 2 independent developer teams that both want to use messaging in their applications. The following diagram describes the flow:
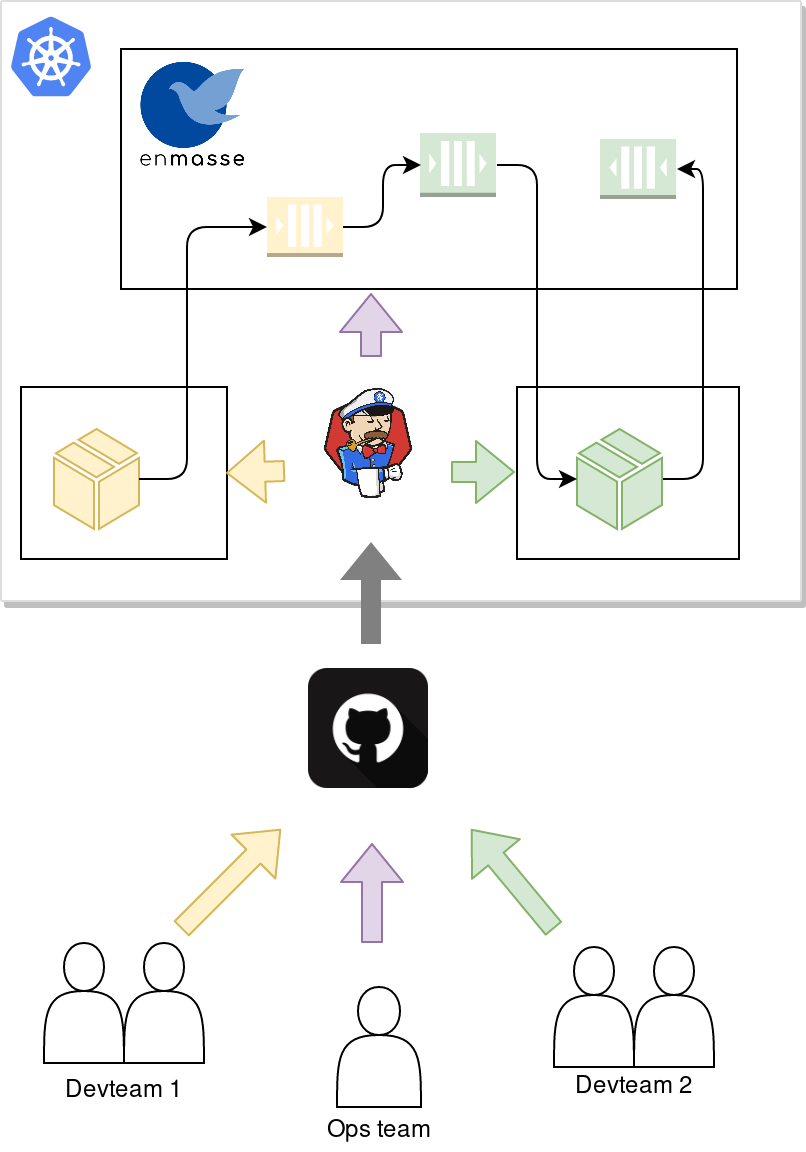
The operations team will deploy the messaging infrastructure (EnMasse), and commit the desired configuration templates that they want to support to git. A CI process then applies the EnMasse configuration to the cluster.
Independently of the operations team, the development teams commit their application code along with the messaging resource manifests, such as AddressSpace, Address and MessagingUser (we will get back to what these are), for their application. A CI process builds the applications and applies the application and messaging resources manifests.
Operations
For the operations team, managing EnMasse in git can be as simple as unpacking the release bundle and committing the parts that is used for a particular installation. In addition, the messaging configuration and available plans must be configured. A sample of the minimal amount of configuration needed can be found here.
Development teams
Application
First, lets create a simple messaging application. Writing messaging clients can be a challenging task, as its asynchronous by nature. The vertx-amqp-client allows you to write simple reactive AMQP 1.0 clients. The following example shows how the application can get all its configuration from the environment:
Vertx vertx = Vertx.vertx();
AmqpClientOptions options = new AmqpClientOptions()
.setSsl(true)
.setPemKeyCertOptions(new PemKeyCertOptions()
.addCertPath(""/var/run/secrets/kubernetes.io/serviceaccount/ca.crt"))
.setHost(System.getenv("MESSAGING_HOST"))
.setPort(Integer.parseInt(System.getenv("MESSAGING_PORT")))
.setUsername("@@serviceaccount@@")
.setPassword(new String(Files.readAllBytes(Paths.get("/var/run/secrets/kubernetes.io/serviceaccount/token")), StandardCharsets.UTF_8));
AmqpClient client = AmqpClient.create(vertx, options);
client.connect(ar -> {
if (ar.succeeded()) {
AmqpConnection connection = ar.result();
connection.createSender("confirmations", done -> {
if (done.succeeded()) {
AmqpSender sender = done.result();
connection.createReceiver("orders"), order -> {
// TODO: Process order
AmqpMessage confirmation = AmqpMessage.create().withBody("Confirmed!").build();
sender.send(confirmation);
}, rdone -> {
if (rdone.succeeded()) {
startPromise.complete();
} else {
startPromise.fail(rdone.cause());
}
});
} else {
startPromise.fail(done.cause());
}
});
} else {
startPromise.fail(ar.cause());
}
});
For full example clients, see example clients.
Messaging resources
Once your application written, some configuration for using the messaging resources available on your cluster is needed.
An EnMasse AddressSpace is a group of addresses that share connection endpoints as well as authentication and authorization policies. When creating an AddressSpace you can configure how your messaging endpoints are exposed:
apiVersion: enmasse.io/v1beta1
kind: AddressSpace
metadata:
name: app
namespace: team1
spec:
type: standard
plan: standard-small
endpoints:
- name: messaging
service: messaging
cert:
provider: openshift
exports:
- name: messaging-config
kind: ConfigMap
For more information about address spaces, see the address space documentation.
Messages are sent and received from an address. An address has a type that determines its semantics, and a plan that determines how much resources is reserved for this address. An address can be defined like this:
apiVersion: enmasse.io/v1beta1
kind: Address
metadata:
name: app.orders
namespace: team1
spec:
address: orders
type: queue
plan: standard-small-queue
To ensure that only trusted applications are able to send and receive messages to your addresses, a messaging user must be created. For applications running on-cluster, you can authenticate clients using a Kubernetes service account. A serviceaccount user can be defined like this:
apiVersion: user.enmasse.io/v1beta1
kind: MessagingUser
metadata:
name: myspace.app
namespace: team1
spec:
username: system:serviceaccount:team1:default
authentication:
type: serviceaccount
authorization:
- operations: ["send", "recv"]
addresses: ["orders"]
With the above 3 resources, you have the basics needed for an application to use the messaging service.
But how does your application get to know the endpoints for its address space? You may have noticed the exports field in the addres space definition. Exports are a way to instruct EnMasse that you want a configmap with the hostname, ports and CA certificate to be created in your namespace. To allow EnMasse to create this resource, we also need to define a Role and RoleBinding for it:
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: messaging-config
namespace: team1
spec:
rules:
- apiGroups: [ "" ]
resources: [ "configmaps" ]
verbs: [ "create" ]
- apiGroups: [ "" ]
resources: [ "configmaps" ]
resourceNames: [ "messaging-config" ]
verbs: [ "get", "update", "patch" ]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: messaging-config
namespace: team1
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: messaging-config
subjects:
- kind: ServiceAccount
name: address-space-controller
namespace: enmasse-infra
Wiring configuration into application
With messaging configuration in place we can write the deployment manifest for our application:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app: myapp
spec:
replicas: 1
template:
metadata:
matchLabels:
application: demo
spec:
containers:
- name: app
image: myapp:latest
env:
- name: MESSAGING_HOST
valueFrom:
configMapKeyRef:
name: messaging-config
key: service.host
- name: MESSAGING_PORT
valueFrom:
configMapKeyRef:
name: messaging-config
key: service.port.amqps
As you can see, the values of the configmap is mapped as environment variables to our application.
Summary
We have seen how an operations team and a set of development teams can manage messaging as Kubernetes manifests. This allows your whole organisation to follow the gitops model when deploying your applications using messaging on Kubernetes and OpenShift.